
In Stata, removing an observation from your dataset can be a useful technique when dealing with missing or invalid data. By removing problematic observations, you can ensure the accuracy and reliability of your analysis.
There are several ways to remove an observation in Stata. One common method is to use the drop command followed by the variables you want to drop. For example, if you want to remove observations where the variable “age” is missing, you can use the command drop if missing(age). This will remove all observations with missing values for the variable “age”.
If you want to remove observations based on certain conditions, you can use the keep command. This command allows you to specify a logical expression to determine which observations should be kept. For example, if you want to keep only observations where the variable “gender” is equal to 1, you can use the command keep if gender == 1. This will remove all observations where the variable “gender” is not equal to 1.
Another way to remove observations is by using the egen command followed by the rowmiss function. This function allows you to create a new variable that represents the number of missing values in each observation. You can then use the drop if command to remove observations with a certain number of missing values. For example, if you want to remove observations with more than 3 missing values, you can use the commands egen missing_values = rowmiss(*) and drop if missing_values > 3.
It is important to note that removing observations should be done with caution and should be based on a valid reason. Removing observations indiscriminately can lead to biased results and invalid conclusions. It is recommended to carefully consider the implications of removing observations and to consult with a statistician or expert if necessary.
Overview of Stata
Stata is a statistical software package widely used by researchers, data analysts, and statisticians. It provides a comprehensive set of tools and functions for data management, statistical analysis, and graphics.
Stata offers a user-friendly interface for data entry and manipulation. You can import data from various file formats, such as Excel, CSV, or SPSS, and perform data cleaning and transformation operations using Stata’s built-in functions.
With Stata, you can conduct a wide range of statistical analyses, including descriptive statistics, regression analysis, time series analysis, and survival analysis. Stata supports a variety of statistical models, such as linear regression, logistic regression, and ANOVA.
In addition to basic statistical procedures, Stata also provides advanced features for handling complex data structures, such as panel data analysis, multilevel modeling, and structural equation modeling. These features make Stata suitable for analyzing data from various fields, including economics, social sciences, health research, and epidemiology.
Stata’s graphics capabilities allow you to create high-quality and customizable graphs and charts to visualize your data. You can generate scatter plots, bar charts, line plots, and more, and customize them with different colors, labels, and markers.
Stata’s powerful programming language, called Stata Programming Language (SPL), allows you to automate repetitive tasks, create custom procedures, and extend Stata’s functionality. With SPL, you can write scripts to perform complex data manipulations and statistical analyses, and save them for future use.
Stata offers comprehensive documentation and resources to support users. The Stata User’s Guide provides detailed information on Stata’s features and functions, and there are numerous online forums and websites where users can seek help and share their experiences with Stata.
Overall, Stata is a powerful and versatile statistical software package that provides a wide range of tools and features for data analysis. Whether you are a beginner or an experienced data analyst, Stata offers the tools you need to explore, analyze, and visualize your data.
What is an Observation in Stata?
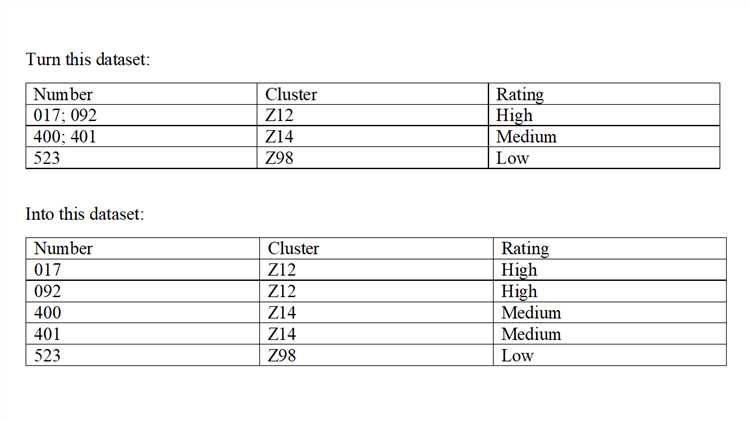
In Stata, an observation refers to a single unit of data in a dataset. It can represent an individual, an organization, a geographic region, or any other defined unit that the dataset is designed to capture information on. Each observation in Stata is typically represented by a single row in the dataset.
An observation is characterized by its variables, which are the columns in the dataset. Each variable contains specific information or attributes about the corresponding observation. For example, in a dataset on individuals, variables might include age, gender, education level, and income.
Observations in Stata can be numeric or character-based. Numeric observations can be continuous (e.g., height or weight) or discrete (e.g., number of children). Character-based observations typically represent categorical or qualitative data, such as the type of occupation or educational attainment level.
The order of observations in Stata datasets is important, as it determines the sequence in which commands and analyses are performed. It is essential to ensure that the dataset is structured correctly and that each observation corresponds to the appropriate variables.
Observations can be manipulated and modified using Stata commands and functions. For example, you can add, delete, or update observations based on specific criteria. Removing an observation can be useful when dealing with missing or erroneous data, outliers, or when conducting statistical analysis on a subset of the dataset.
Understanding the concept of an observation is crucial when working with Stata, as it forms the basis for data analysis and manipulation. By correctly identifying and managing observations, researchers and analysts can draw meaningful insights from their datasets and make informed decisions based on empirical evidence.
Why would you want to remove an Observation?
There are several reasons why you might need to remove an observation from your dataset in Stata:
- Data entry errors: If there was a mistake made when entering data into the dataset, you may want to remove the observation to ensure the accuracy of your analysis.
- Outliers: Outliers are extreme values that can have a disproportionate effect on your analysis. Removing these observations can help improve the robustness of your results.
- Incomplete or missing data: If an observation has missing values for important variables, you may want to remove it to avoid biasing your analysis.
- Sampling errors: In some cases, an observation may have been included in your dataset by mistake or due to an error in sampling. Removing such observations can help ensure the integrity of your analysis.
Regardless of the specific reason, removing observations is a common data cleaning and preprocessing step that is often necessary to ensure the accuracy and reliability of your analysis in Stata.
Step-by-step guide to removing an Observation
Removing an observation in Stata can be done using the drop command. This command allows you to remove specific observations from your dataset based on certain criteria. Follow the steps below to remove an observation in Stata:
- Identify the criteria: Determine the criteria based on which you want to remove the observation. This could be a specific value in a variable, a range of values, or any other condition that you want to apply.
- Open the dataset: Open the dataset in Stata that contains the observation you want to remove. You can do this by using the
usecommand followed by the filepath of the dataset. For example,use "C:\data\dataset.dta". - View the dataset: Check the dataset to verify the observation you want to remove. You can use the
listcommand to view the dataset in the Stata Results window. - Create a new variable: If necessary, create a new variable to store the results of the removal. This step is optional but can be useful to keep track of the observations that have been removed. You can use the
gencommand to create a new variable. - Remove the observation: Use the
dropcommand to remove the observation based on the criteria you identified in Step 1. For example, if you want to remove all observations where the variable “age” is greater than 60, you can use the following command:drop if age > 60. - Save the modified dataset: After removing the desired observation, save the modified dataset using the
savecommand. This will ensure that the changes are permanently saved. For example,save "C:\data\modified_dataset.dta".
Following these steps will allow you to successfully remove an observation from your dataset in Stata. It is important to carefully consider the criteria and verify the changes before saving the modified dataset.
Common issues when removing Observations
When removing observations in Stata, there are several common issues that you may encounter. It is important to be aware of these issues to ensure that you are correctly removing the intended observations and avoiding potential errors.
- Missing data: If your dataset contains missing values, removing observations may lead to unintended consequences. It is important to carefully consider the impact of missing data on your analysis and decide whether to code missing values before removing any observations.
- Sample selection bias: Removing observations without careful consideration may introduce sample selection bias, which can impact the validity of your results. Ensure that the observations you are removing do not disproportionately affect the characteristics of your sample or introduce bias into your analysis.
- Data dependencies: Removing observations may disrupt data dependencies and relationships. If your analysis relies on the relationship between observations, removing one observation may affect the validity of your results. Consider the implications of removing observations on the integrity of your analysis.
- Data preservation: When removing observations, it is crucial to preserve the integrity of your dataset. Make sure to keep a backup of the original dataset or create a new dataset with the removed observations. This will allow for traceability and reproducibility of your analysis.
- Documentation: Always document the reasons for removing observations in your analysis. This will help to ensure transparency and allow others to understand the decisions made during the data cleaning process.
Alternative methods for handling Observations
In addition to the drop command, there are several other methods available in Stata for handling observations in your dataset. Here are a few alternatives:
- Keep command: The keep command allows you to specify which variables you want to keep in your dataset, rather than dropping variables or observations that you want to remove. This can be useful when you only want to retain a subset of your variables.
- Filter command: The filter command is another alternative to the drop command. It allows you to create a new dataset that includes only the observations that meet certain criteria. This can be useful when you want to create a subset of your dataset based on specific conditions.
- Recall command: The recall command allows you to restore a previously saved version of your dataset, which can be useful if you made a mistake while modifying your dataset and want to revert back to a previous version.
- Missing values: Instead of completely removing observations, you can also handle them by assigning missing values to specific variables using the missing command. This way, you can keep the observations in your dataset but indicate that certain values are missing or invalid.
It’s important to carefully consider which method is best suited for your specific analysis and dataset. Each method has its own advantages and limitations, so understanding their differences can help you make informed decisions when handling observations in Stata.
Remember to always make a backup of your dataset before making any changes or modifications, as it can help prevent data loss and allow you to revert back to the original version if needed.
FAQ:
What is Stata?
Stata is a statistical software package that provides a wide range of tools for data analysis and visualization.
Why would I want to remove an observation in Stata?
You may want to remove an observation in Stata if it is an outlier or contains errors that could affect your analysis results.
How do I remove an observation in Stata?
To remove an observation in Stata, you can use the `drop` command followed by the observation number or a condition. For example, `drop if observation_number == 5` will remove the fifth observation.
Can I remove multiple observations at once in Stata?
Yes, you can remove multiple observations at once in Stata. You can use the `drop` command followed by a condition that includes multiple observation numbers or a range of observation numbers.
How can I remove observations based on a condition?
To remove observations based on a condition in Stata, you can use the `drop` command followed by the condition you want to apply. For example, `drop if variable_name > 10` will remove all observations where the variable_name is greater than 10.
Is it possible to remove observations and save them in a separate dataset in Stata?
Yes, it is possible to remove observations and save them in a separate dataset in Stata. You can use the `save` command to save the dataset with the removed observations to a new file.
What are some alternative ways to handle outliers or problematic observations instead of removing them in Stata?
Instead of removing outliers or problematic observations in Stata, you can consider transforming the data, winsorization (replacing extreme values with less extreme values), imputing missing values, or using robust statistical methods.